Most LLM driven apps work well when the answer is obvious and short. They start to struggle when the answer is buried in a long document (context), split across sections, or only becomes clear after inspecting several nearby passages. That is exactly the kind of problem that RLM is designed for and this post explains the idea in simple terms, shows why it matters, and walks through a small example you can actually reason about.
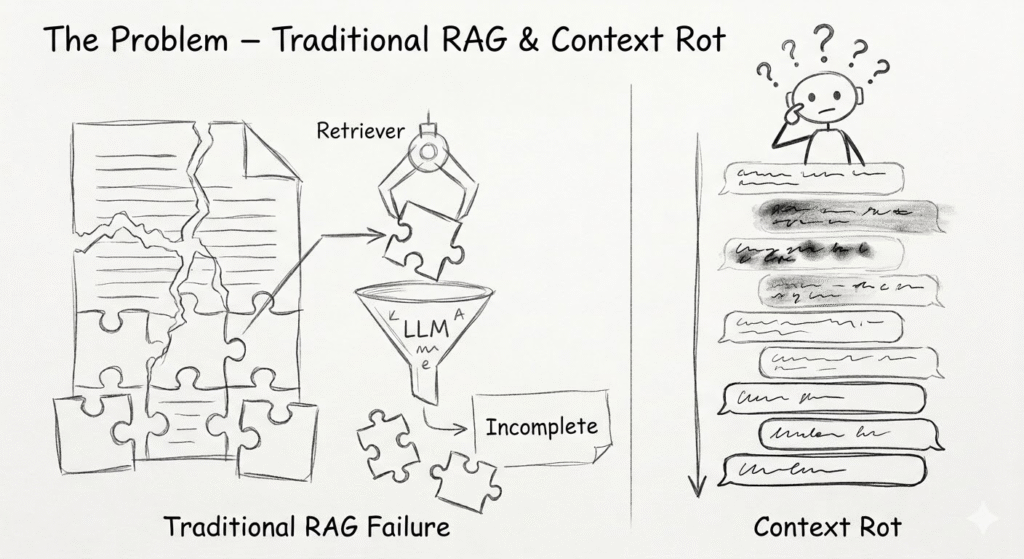
If you have built with retrieval-augmented generation (RAG), you already know the first version of the problem: get the right chunks, inject them into the prompt, and hope the model answers well. That works surprisingly far, but it does not fully solve the harder cases. As documents get larger, the useful evidence is often spread across sections, tables, footnotes, appendices, or even separate files. As conversations get longer, the model can also drift into the familiar long-context failure mode often described as context rot – the conversation keeps growing, but the quality of reasoning can quietly degrade.
That is where recursive language models become interesting. Instead of treating the whole task as a single prompt-and-response problem, RLM keeps the model in a loop where it can inspect context, narrow the search space, recurse when needed, and only then produce a final answer. The original RLM writeup by Alex Zhang and collaborators is a good reference point for this idea: the goal is not just to answer with more tokens, but to make long-context reasoning more reliable by giving the model an explicit exploration process.
Simple Analogy:
Think about finding one specific photo in a huge phone gallery.
You do not stare at the entire gallery and try to memorize everything at once. You scroll a bit, check the date, open an album, zoom in, go back, and keep narrowing the search until you find the right photo.
This is mental model for RLM
- the document is the gallery
- the ability to run small bits of code to search the document is the scrolling and zooming
- the intermediate steps are your quick checks
- the final answer is the photo you were trying to find
This is a much better than “just ask the model harder.”
The Core Idea:
A normal prompt asks the model to answer in one shot. An RLM lets the model explore.
That difference matters a lot for lengthy documents. Instead of forcing the model to guess from memory or rely on a single pass, RLM gives it a loop:
- Inspect part of the document
- Search for relevant text
- Reason over what it found
- Inspect again if needed
- Submit only when the answer is ready
In practice, that means the model can behave less like a one-shot generator and more like a careful analyst.
Why this matters for long-context scenarios:
Long documents are difficult for a few simple reasons:
- the answer is not in one place
- the key value appears in a table on one page and the explanation on another
- nearby passage can look relevant but still be incomplete
- the final answer needs evidence, not just a guess
- the document is too large to reason about reliably in a single pass
This is where many LLM based systems start adding brittle chunking logic, ad hoc search steps, or complicated prompt chains. Those approaches can work, but they often become fragile as the document format changes.
RLM is attractive because it gives the model a controlled exploration loop instead of forcing you to hard-code every search step yourself.
What RLM is actually doing:
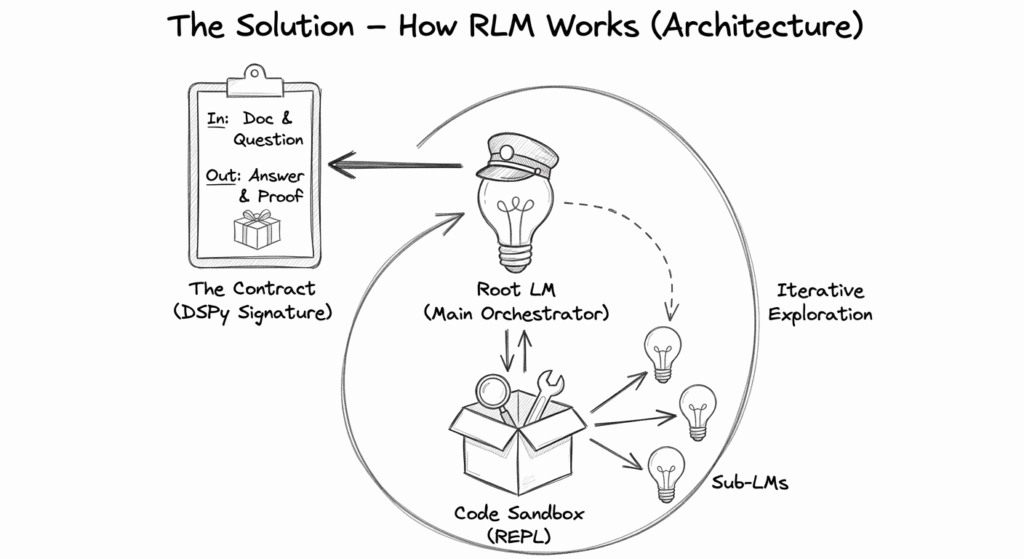
Under the hood, RLM is not simply “thinking harder.” It is running a loop where the model can inspect context, execute small pieces of code (usually in a sandbox Python REPL i.e. READ EVAL PRINT LOOP), and refine its understanding before answering.
This makes it extremely powerful when:
- the relevant text is far apart
- the document is too large
- the answer depends on nearby context
- the models needs to search before answering
This is why RLM fits document intelligence, policy reading, contract analysis, report extraction and similar use cases so well.
What DSPy adds:
If RLM is the idea, DSPy is the tool to build it. DSPy is a framework for programming – not prompting, language models. Instead of writing brittle prompt strings, you write declarative modules that the framework can optimize and execute. It is the perfect home for the RLM pattern because it treats the LLM like a piece of software infrastructure.
With DSPy signatures, you define:
- what the input is
- what the output should look like
- how the model should interpret the task
That matters because the output is no longer an unstructured paragraph. It can be typed, validated, and used downstream. In other words, DSPy helps turn the RLM loop into a contract.
What is DSPy signature?
In DSPy, a signature is a declarative definition of a task. Think of it like a function signature in traditional programming: it defines the inputs, the outputs, and a brief description of what the task is supposed to accomplish. It tells the model what to do, without micromanaging how to prompt it.
For quick prototypes, you can write a signature as a simple string:
rlm = dspy.RLM("document, question -> answer", max_iterations=10) That shorthand tells the RLM exactly what variables to work with (left of the arrow) and what to produce (right of the arrow).
But when you are building real applications, you want richer control. That is where class-based signatures come in. They let you attach data types, detailed descriptions, and complex output structures.
Instead of a plain string, you define a proper Python class. Conceptually, it is the same idea, but a class-based signature gives the RLM the structure it needs to return reliable, typed data.
Putting the pattern into code:
Here’s the simple version of the pattern
import dspy
class DocumentAnswerSignature(dspy.Signature):
# 1. The docstring becomes the system instruction.
# This tells the RLM exactly what its overall job is.
"""Answer a question by carefully exploring a long document."""
# 2. InputFields define what we give the model.
# The 'desc' helps the model understand the nature of the input.
document: str = dspy.InputField(
desc="Full text of a long document, policy or manual."
)
question: str = dspy.InputField(
desc="The specific question to answer from the document."
)
# 3. OutputFields define what we want back.
# The model will not stop its REPL loop until it is confident it can populate these.
answer: str = dspy.OutputField(
desc="The final answer grounded in the document."
)
evidence: str = dspy.OutputField(
desc="A short verbatim quote showing exactly where the answer came from."
)
rlm = dspy.RLM(
DocumentAnswerSignature,
# Give the model a budget to run Python code and search
# before it is forced to submit a final answer.
max_iterations=10,
)
result = rlm(document=long_text, question="What is the key decision?")
print(result.answer)
print(result.evidence) The point here is not the exact code, but point is the shape of the interaction i.e.
- a long document comes in
- the model explorers it iteratively
- the output is structured
- the result is earlier to trust and reuse
Visual of the loop
Best practices I learned while building with RLM
A few practical lessons stand out:
- keep the signature narrow and well defined
- make output fields explicit and typed
- describe the fields carefully
- give the model room to search, not just answer
- do not overcomplicate the first version
- use RLM when search and extraction matter more than free-form generation
- capture reasoning and source text when auditability matters
Why this feels like a game changer to me:
A lot of agentic engineering today still assumes one of two things i.e. the model already knows enough or the developer must manually orchestrate every step.
RLM sits in a better middle ground as it gives the model a controlled space to explore, while DSPy gives you a clean contract for the output.
That combination is powerful because it reduces brittle prompt engineering and makes long-context work much more systematic.
Closing thoughts:
If you are building apps around long documents, RLM is worth understanding.
The key shift is simple: stop asking the model to guess from a single pass, and start letting it explore like a careful analyst.
Once you see that pattern, a lot of hard document tasks become more approachable.
And once you pair it with DSPy signatures, the result is not just clever – it is structured, auditable, and production-friendly.