For organizations leveraging OpenAI’s Agent SDK, one of the most important metrics to track is token usage. Tokens are the fundamental units of text processing in large language models, and they directly impact both performance and cost.
This post explores how to track token usage in applications built with the OpenAI Agent SDK discusses the broader implications for organizations.
Understanding Tokens in LLMs
Before diving into the technical details, let’s clarify what tokens are and why they matter:
What are Tokens?
Tokens are the fundamental units of text that language models process. Unlike traditional word-based processing, large language models like GPT break down text into smaller pieces called tokens. Understanding tokens is crucial for effectively working with these models:
Token Basics
- In English, a token is roughly equivalent to 4 characters or 3/4 of a word on average
- Common words like “the” or “and” are typically single tokens
- Longer or uncommon words get split into multiple tokens
- Spaces, punctuation, and special characters also count as tokens
Token Types
Input Tokens: These represent the tokens consumed by your prompts and instructions sent to the model. Longer, more detailed prompts will use more input tokens.
Output Tokens: These are the tokens generated by the model in its responses. More detailed or lengthy responses will consume more output tokens.
Total Tokens: The sum of input and output tokens, representing the overall token consumption for a particular interaction.
Cached Tokens: When the system reuses previously processed text, these tokens don’t incur additional charges. These tokens were served from cache rather than processed as new tokens.
Reasoning Tokens: For models that support chain-of-thought or step-by-step reasoning, this metric indicates how many tokens were used in the reasoning process before generating the final answer. These are not considered while doing calculations of the total cost, these are internal values and are only for the reference.
Why Token Tracking Matters?
Cost Management: Most AI service providers, including OpenAI, charge based on token usage. Understanding the application’s token consumption is essential for budgeting and cost optimization.
Performance Optimization: Models have context length limitations. Tracking token usage helps ensure your applications stay within these constraints while maximizing the value of each token.
Resource Planning: Predictable token usage patterns allow for better capacity planning and resource allocation.
Token Tracking with OpenAI Agent SDK
Let’s look at an example of how to track token usage in an application built with the OpenAI Agent SDK.
Output
When you run the code example provided earlier, you might see output like this:
Final output: Why don't skeletons fight each other?
They don't have the guts!
Token Usage Information:
Input tokens: 27
Output tokens: 16
Total tokens: 43
Cached tokens: 0
Reasoning tokens: 0
Number of requests: 1Sample Usage Calculations
Understanding how token usage translates to actual costs is important for budgeting and optimization. Let’s walk through some sample calculations using different models:
Let’s consider above tokens from one run of an agent, from Azure cost calculator – the price of GPT4o model as of today is as below
Input tokens: $2.5 per million tokens which translates to $0.0000025 per token
Output tokens: $10 per million which translates to $0.00001 per token
Cached tokens: $1.25 per million tokens which translates to $0.00000125 per token
The formula for calculating the total cost then becomes as below:
Total Cost = (Uncached Input Tokens × Input Token Price) + (Cached Input Tokens × Cached Token Price) + (Output Tokens × Output Token Price)
With this formula. for this example, the total agent run cost becomes = $0.066294
So what are key lessons?
Based on the lessons learnt: here is some practical guidelines for optimizing prompts and interactions with large language models:
DOs:
- Use craft clear, direct prompts that get to the point. Remove unnecessary context or verbose explanations unless they’re essential for the task.
- Be aware that system messages persist throughout a conversation and count toward your token usage. Keep them focused on critical instructions rather than lengthy explanations.
DON’Ts:
- Don’t repeat information that’s already been shared in the conversation or that isn’t relevant to the current query. (Token caching exists, we know but as a good practice try not to send same data again).
- Resist the urge to provide excessive examples or explanations in your prompts when a simpler instruction would suffice.
- Instead of sending entire documents for analysis, extract and send only the relevant sections to minimize token consumption.
Conclusion:
Token usage monitoring is not just about controlling costs, it’s about building sustainable, efficient AI systems that deliver maximum value.
By implementing the tracking techniques in your agent SDK frameworks, organizations can gain visibility into their AI resource consumption, optimize their applications, and make better decisions about their AI investments.
As the adoption of AI continues to grow, those who learn the art and science of token usage management will have a significant advantage to get better value for their bucks aka ROI.
Cost Calculator Tool
I’ve also created a simple tool that enables you and your team to calculate the total operational cost of your model and interactions. By inputting values and configuring the pricing settings, the tool provides a cost breakdown similar to the example below.
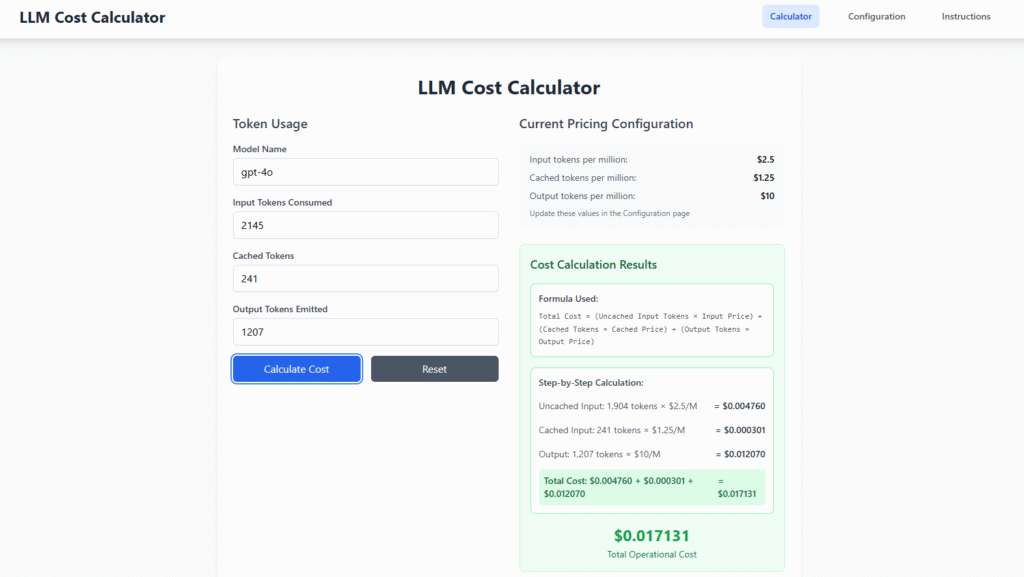
It’s a basic React.js application that you can download from my repository and host yourself for your own use. You can find the link to the repository in the references section.