Most AI applications today use RAG (Retrieval-Augmented Generation) to work with private data. The typical approach? Convert text into vectors and search for similar content. It works well, but it has a big limitation: it can’t see how different pieces of information connect to each other.
Think about it like this – traditional RAG (sometimes referred as baseline RAG) reads each paragraph in isolation, but what if your data has hidden relationships? What if understanding the full picture requires connecting dots across multiple documents?
That’s where Graph RAG comes in. Instead of treating text as isolated chunks, it builds a knowledge graph that captures relationships between entities. I recently built a Graph RAG system from scratch to see how it compares to traditional approaches. In this series, I’ll share what I learned – the good, the bad, and the surprisingly tricky parts of building something that actually works.
What is Graph RAG and Why Does It Matter?
At its core, Graph RAG improves the “retrieval” step by searching over a structured graph of entities and relationships, rather than just a collection of text chunks.
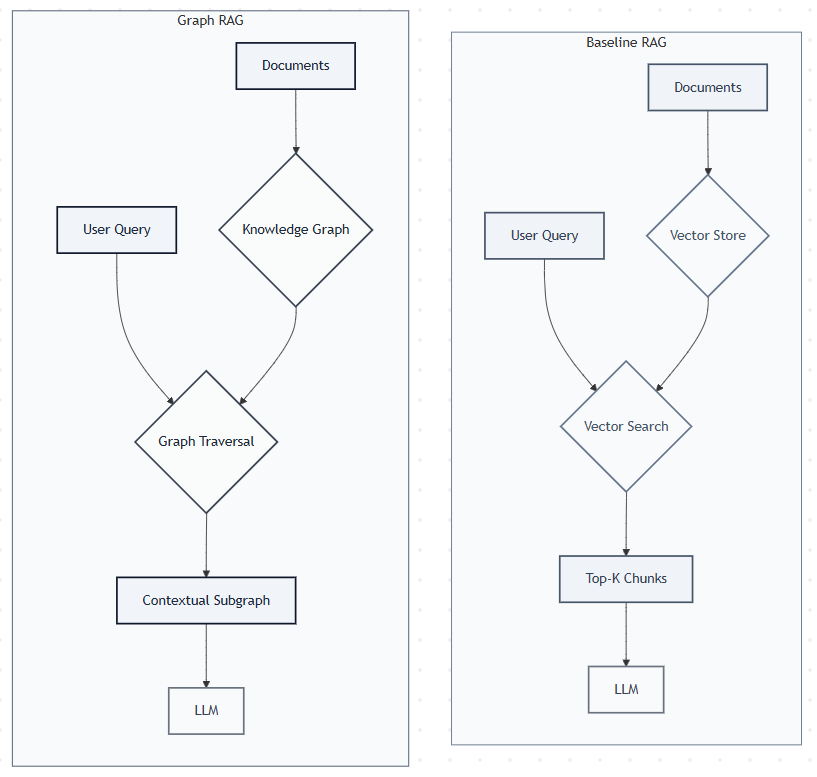
While baseline RAG is excellent for finding direct answers, it struggles with questions that require connecting multiple pieces of information. For example, in a business context, answering “Which products are frequently bought together by customers in similar segments?” requires linking products to customer behaviors and market segments. A simple vector search might miss these multi-hop connections entirely. Graph RAG excels here, as it can traverse the graph to find related entities and aggregate comprehensive answers.
A Quick Primer on Graph Models: LPG vs. RDF
- Labeled Property Graph (LPG): This is the model I used. It consists of nodes (entities) and relationships (edges). Both nodes and relationships can have labels and arbitrary key-value properties. This flexibility is ideal for representing diverse, real-world data across different domains. Neo4j is a popular LPG database.
- Resource Description Framework (RDF): RDF uses triples (subject-predicate-object) to make statements. It’s a W3C standard, highly structured, and excellent for data interchange on the web, but can be more rigid than the LPG model for some applications.
I chose the LPG model for its intuitive structure and rich property support, which works well across different domains including the sample data I used for testing.
Graph Creation: From Raw Text to Structured Knowledge
Building the knowledge graph is the most critical—and challenging—part of the process. It’s not a simple file conversion, it’s a resource-intensive task that demands careful planning.
Key Challenges
- Time and Compute: Using an LLM to read through documents and extract structured entities and relationships is slow and can be expensive, especially with large datasets.
- Schema Design: What should be a node? What defines a relationship? I had to carefully design a schema that was specific enough to be useful but general enough to capture the richness of the data.
- Entity and Relationship Tuning: The initial output from the LLM is never perfect. This went through several iterations of prompt engineering to guide the model to correctly identify entities and their connections.
Building the Pipeline: Raw Implementation vs Framework
The Traditional Approach
My first attempt was a “raw” implementation. I wrote Python scripts that manually handled every step of the process: reading the text, chunking it, formatting a prompt for GPT-4o hosted on Azure AI Foundry, and parsing the returned JSON to create Cypher statements for Neo4j.
Here’s a simplified look at the core logic from traditional-approach/ingestion-raw.py
Pros:
- Full Control: I had granular control over every detail, from the prompt structure to the exact Cypher queries.
- Great for Learning: It forced me to understand the fundamentals of graph creation from the ground up.
Cons
- Brittle and Verbose: he code was highly specific to my schema and required a lot of boilerplate for error handling, retries, and data validation.
- Hard to Adapt: Changing the schema meant significant code rewrites.
Framework (LangChain) Approach
Feeling the pain of the manual approach, I turned to LangChain’s experimental graph transformers. The LLMGraphTransformer abstracts away much of the complexity. Instead of manually crafting prompts and parsing JSON, I could configure the transformer with my schema and let it handle the heavy lifting.
This is the core of my LangChain implementation in langchain/ingestion-langchain.py
Pros
- Rapid Development: The abstraction allowed me to focus on schema design and prompt engineering rather than boilerplate code. This was a huge productivity boost.
- Schema-Driven: By defining my schema in CSV files, I could easily modify the graph structure without touching the ingestion code.
- Robustness: LangChain handles the underlying API calls, retries, and data structuring, making the pipeline more resilient.
Cons
- Framework Lock-in: The implementation becomes tightly coupled to LangChain’s architecture and design decisions.
- Hidden Complexity: The abstraction can mask important details about token usage, retry logic, and error handling that affect production deployments.
- Versioning Challenges: Framework updates might change behavior in subtle ways that affect your graph quality without obvious errors.
Why GPT-4o on Azure AI Foundry?
I chose GPT-4o for its superior reasoning capabilities and structured output reliability – important for consistent graph extraction.
Azure AI Foundry made this choice even better by providing enterprise-grade hosting with built-in monitoring, security compliance, and easy scaling. The platform’s integration with other Azure services also opened up possibilities for future enhancements like automated pipelines and advanced analytics.
A Note on Microsoft’s Graph RAG Accelerator
During my research, I also looked into Microsoft’s Graph RAG offerings. While their open-source graphrag library is actively developed, the associated graphrag-accelerator repository on GitHub, I see very less contributions to it so not sure about it’s active maintenance.
This lack of a clear roadmap for an integrated, easy-to-deploy solution was a concern and reinforced my decision to build my own pipeline using more stable, community-supported tools like LangChain and Neo4j.
Key Takeaways and What’s Next
Building a Graph RAG system from scratch taught me that the real challenge isn’t just about choosing between traditional RAG and Graph RAG – it’s about understanding when the added complexity pays off. Graph RAG shines when your data has rich interconnections that traditional vector search simply can’t capture. But it comes with significant engineering overhead that you need to plan for.
Most importantly, this implementation reminded me that successful AI implementations are rarely about finding the perfect tool – they’re about understanding the trade-offs and building something that actually works reliably. The LangChain approach won not because it was theoretically superior, but because it let me iterate faster and focus on the problems that truly mattered.
But here’s the thing: building the knowledge graph is only half the battle. The real test of Graph RAG comes when users start asking questions. Can the system actually leverage those carefully constructed relationships to provide better answers than traditional RAG?
In Part 2 of this series, I will dive into the retrieval and question-answering side of my implementation, exploring how I used LangChain’s GraphCypherQAChain to query the knowledge graph and the many prompt engineering iterations it took to get it right.